Scale-free network
A scale-free network is a network whose degree distribution follows a power law, at least asymptotically. That is, the fraction P(k) of nodes in the network having k connections to other nodes goes for large values of k as
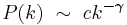
where 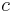 is a normalization constant and
is a normalization constant and 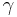 is a parameter whose value is typically in the range 2 < < 3, although occasionally it may lie outside these bounds.
is a parameter whose value is typically in the range 2 < < 3, although occasionally it may lie outside these bounds.
Contents |
Highlights
- Many networks are conjectured to be scale-free, including World Wide Web links, biological networks, and social networks, although the scientific community is still discussing these claims as more sophisticated data analysis techniques become available.[1]
- The mechanism of preferential attachment and the fitness model have been proposed as a mechanisms to explain conjectured power law degree distributions in real networks.
History
In studies of the networks of citations between scientific papers, Derek de Solla Price showed in 1965 that the number of links to papers—i.e., the number of citations they receive—had a heavy-tailed distribution following a Pareto distribution or power law, and thus that the citation network is scale-free. He did not however use the term "scale-free network", which was not coined until some decades later. In a later paper in 1976, Price also proposed a mechanism to explain the occurrence of power laws in citation networks, which he called "cumulative advantage" but which is today more commonly known under the name preferential attachment.
Recent interest in scale-free networks started in 1999 with work by Albert-László Barabási and colleagues at the University of Notre Dame who mapped the topology of a portion of the World Wide Web,[2] finding that some nodes, which they called "hubs", had many more connections than others and that the network as a whole had a power-law distribution of the number of links connecting to a node. After finding that a few other networks, including some social and biological networks, also had heavy-tailed degree distributions, Barabási and collaborators coined the term "scale-free network" to describe the class of networks that exhibit a power-law degree distribution. Amaral et al. showed that most of the real-world networks can be classified into two large categories according to the decay of degree distribution P(k) for large k.
Barabási and Albert proposed a generative mechanism to explain the appearance of power-law distributions, which they called "preferential attachment" and which is essentially the same as that proposed by Price. Analytic solutions for this mechanism (also similar to the solution of Price) were presented in 2000 by Dorogovtsev, Mendes and Samukhin and independently by Krapivsky, Redner , and Leyvraz, and later rigorously proved by mathematician Béla Bollobás.[3] Notably, however, this mechanism only produces a specific subset of networks in the scale-free class, and many alternative mechanisms have been discovered since.
The history of scale-free networks also includes some disagreement. On an empirical level, the scale-free nature of several networks has been called into question. For instance, the three brothers Faloutsos believed that the Internet had a power law degree distribution on the basis of traceroute data; however, it has been suggested that this is a layer 3 illusion created by routers, which appear as high-degree nodes while concealing the internal layer 2 structure of the ASes they interconnect. [4] On a theoretical level, refinements to the abstract definition of scale-free have been proposed. For example, Li et al. (2005) recently offered a potentially more precise "scale-free metric". Briefly, let g be a graph with edge-set ε, and let the degree (number of edges) at a vertex i be 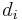 . Define
. Define
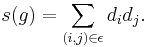
This is maximized when high-degree nodes are connected to other high-degree nodes. Now define
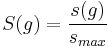
where smax is the maximum value of s(h) for h in the set of all graphs with an identical degree distribution to g. This gives a metric between 0 and 1, such that graphs with low S(g) are "scale-rich", and graphs with S(g) close to 1 are "scale-free". This definition captures the notion of self-similarity implied in the name "scale-free".
Characteristics
The most notable characteristic in a scale-free network is the relative commonness of vertices with a degree that greatly exceeds the average. The highest-degree nodes are often called "hubs", and are thought to serve specific purposes in their networks, although this depends greatly on the domain.
The scale-free property strongly correlates with the network's robustness to failure. It turns out that the major hubs are closely followed by smaller ones. These ones, in turn, are followed by other nodes with an even smaller degree and so on. This hierarchy allows for a fault tolerant behavior. If failures occur at random and the vast majority of nodes are those with small degree, the likelihood that a hub would be affected is almost negligible. Even if a hub-failure occurs, the network will generally not lose its connectedness, due to the remaining hubs. On the other hand, if we choose a few major hubs and take them out of the network, the network is turned into a set of rather isolated graphs. Thus, hubs are both a strength and a weakness of scale-free networks. These properties have been studied analytically using percolation theory by Cohen et al.[5][6] and by Callaway et al.[7]
Another important characteristic of scale-free networks is the clustering coefficient distribution, which decreases as the node degree increases. This distribution also follows a power law. This implies that the low-degree nodes belong to very dense sub-graphs and those sub-graphs are connected to each other through hubs. Consider a social network in which nodes are people and links are acquaintance relationships between people. It is easy to see that people tend to form communities, i.e., small groups in which everyone knows everyone (one can think of such community as a complete graph). In addition, the members of a community also have a few acquaintance relationships to people outside that community. Some people, however, are connected to a large number of communities (e.g., celebrities, politicians). Those people may be considered the hubs responsible for the small-world phenomenon.
At present, the more specific characteristics of scale-free networks vary with the generative mechanism used to create them. For instance, networks generated by preferential attachment typically place the high-degree vertices in the middle of the network, connecting them together to form a core, with progressively lower-degree nodes making up the regions between the core and the periphery. The random removal of even a large fraction of vertices impacts the overall connectedness of the network very little, suggesting that such topologies could be useful for security, while targeted attacks destroys the connectedness very quickly. Other scale-free networks, which place the high-degree vertices at the periphery, do not exhibit these properties. Similarly, the clustering coefficient of scale-free networks can vary significantly depending on other topological details.
A final characteristic concerns the average distance between two vertices in a network. As with most disordered networks, such as the small world network model, this distance is very small relative to a highly ordered network such as a lattice graph. Notably, an uncorrelated power-law graph having 2 < γ < 3 will have ultrasmall diameter d ~ ln ln N where N is the number of nodes in the network, as proved by Cohen and Havlin. The diameter of a growing scale-free network might be considered almost constant in practice.
Examples
Although many real-world networks are thought to be scale-free, the evidence often remains inconclusive, primarily due to the developing awareness of more rigorous data analysis techniques.[1] As such, the scale-free nature of many networks is still being debated by the scientific community. A few examples of networks claimed to be scale-free include:
- Social networks, including collaboration networks. An example that has been studied extensively is the collaboration of movie actors in films.
- Sexual partners in humans, which affects the dispersal of sexually transmitted diseases.
- Many kinds of computer networks, including the internet and the webgraph of the World Wide Web.
- Protein-Protein interaction networks.
- Semantic networks.[8]
- Airline networks.
Scale free topology has been also found in high temperature superconductors.[9] The qualities of a high-temperature superconductor — a compound in which electrons obey the laws of quantum physics, and flow in perfect synchrony, without friction — appear linked to the fractal arrangements of seemingly random oxygen atoms.
Generative models
These scale-free networks do not arise by chance alone. Erdős and Rényi (1960) studied a model of growth for graphs in which, at each step, two nodes are chosen uniformly at random and a link is inserted between them. The properties of these random graphs are different from the properties found in scale-free networks, and therefore a model for this growth process is needed.
The mostly widely known generative model for a subset of scale-free networks is Barabási and Albert's (1999) rich get richer generative model in which each new Web page creates links to existing Web pages with a probability distribution which is not uniform, but proportional to the current in-degree of Web pages. This model was originally discovered by Derek J. de Solla Price in 1965 under the term cumulative advantage, but did not reach popularity until Barabási rediscovered the results under its current name (BA Model). According to this process, a page with many in-links will attract more in-links than a regular page. This generates a power-law but the resulting graph differs from the actual Web graph in other properties such as the presence of small tightly connected communities. More general models and networks characteristics have been proposed and studied (for a review see the book by Dorogovtsev and Mendes).
A somewhat different generative model for Web links has been suggested by Pennock et al. (2002). They examined communities with interests in a specific topic such as the home pages of universities, public companies, newspapers or scientists, and discarded the major hubs of the Web. In this case, the distribution of links was no longer a power law but resembled a normal distribution. Based on these observations, the authors proposed a generative model that mixes preferential attachment with a baseline probability of gaining a link.
Another generative model is the copy model studied by Kumar et al. (2000), in which new nodes choose an existent node at random and copy a fraction of the links of the existent node. This also generates a power law.
Interestingly, the growth of the networks (adding new nodes) is not a necessary condition for creating a scale-free network. Dangalchev (2004) gives examples of generating static scale-free networks. Another possibility (Caldarelli et al. 2002) is to consider the structure as static and draw a link between vertices according to a particular property of the two vertices involved. Once specified the statistical distribution for these vertices properties (fitnesses), it turns out that in some circumstances also static networks develop scale-free properties.
Scale-free ideal network
In the context of network theory a scale-free ideal network is a random network with a degree distribution following the scale-free ideal gas density distribution. These networks have the special property of reproducing the city-size distribution and electoral results unravelling the size distribution of social groups with information theory on complex networks,[10] when a competitive cluster growth process[11] is applied to the network. In models of scale-free ideal networks it is possible to demonstrate that Dunbar's number is the cause of the phenomenon known as the 'six degrees of separation' .
See also
- Social-circles network model - a more generalized generative model for many "real-world networks" of which the scale-free network is a special case
- Random graph
- Erdős–Rényi model
- Bose-Einstein condensation: a network theory approach
- Scale invariance
- Complex network
- Webgraph
References
- ^ a b Clauset, Aaron; Cosma Rohilla Shalizi, M. E. J Newman (2007-06-07). "Power-law distributions in empirical data". 0706.1062. arXiv:0706.1062. doi:10.1137/070710111.
- ^ Barabási, Albert-László; Albert, Réka. (October 15, 1999). "Emergence of scaling in random networks". Science 286 (5439): 509–512. arXiv:cond-mat/9910332. doi:10.1126/science.286.5439.509. MR2091634.
- ^ Bollobás, B.; Riordan, O.; Spencer, J.; Tusnády, G. (2001). "The degree sequence of a scale-free random graph process". Random Structures and Algorithms 18 (3): 279–290. doi:10.1002/rsa.1009. MR1824277.
- ^ Willinger, Walter; David Alderson, and John C. Doyle (2009-5). "Mathematics and the Internet: A Source of Enormous Confusion and Great Potential". Notices of the AMS (American Mathematical Society) 56 (5): 586–599. http://authors.library.caltech.edu/15631/1/Willinger2009p5466Notices_Amer._Math._Soc.pdf. Retrieved 2011-02-03.
- ^ Cohen, Reoven; K. Erez, D. ben-Avraham and S. Havlin (2000). "Resilience of the Internet to Random Breakdowns". Phys. Rev. Lett. 85: 4626–8. Bibcode 2000PhRvL..85.4626C. doi:10.1103/PhysRevLett.85.4626. http://link.aps.org/doi/10.1103/PhysRevLett.85.4626.
- ^ Cohen, Reoven; K. Erez, D. ben-Avraham and S. Havlin (2001). "Breakdown of the Internet under Intentional Attack". Phys. Rev. Lett. 86: 3682–5. Bibcode 2001PhRvL..86.3682C. doi:10.1103/PhysRevLett.86.3682. PMID 11328053. http://link.aps.org/doi/10.1103/PhysRevLett.86.3682.
- ^ Callaway, Duncan S.; M. E. J. Newman, S. H. Strogatz and D. J. Watts (2000). "Network Robustness and Fragility: Percolation on Random Graphs". Phys. Rev. Lett. 85: 5468–71. Bibcode 2000PhRvL..85.5468C. doi:10.1103/PhysRevLett.85.5468. http://link.aps.org/doi/10.1103/PhysRevLett.85.5468.
- ^ Steyvers, Mark; Joshua B. Tenenbaum (2005). "The Large-Scale Structure of Semantic Networks: Statistical Analyses and a Model of Semantic Growth". Cognitive Science 29 (1): 41–78. doi:10.1207/s15516709cog2901_3. http://www.leaonline.com/doi/abs/10.1207/s15516709cog2901_3.
- ^ Fratini, Michela, Poccia, Nicola, Ricci, Alessandro, Campi, Gaetano, Burghammer, Manfred, Aeppli, Gabriel Bianconi, Antonio (2010). "Scale-free structural organization of oxygen interstitials in La2CuO4+y". Nature 466 (7308): 841–4. doi:10.1038/nature09260. PMID 20703301. http://www.nature.com/nature/journal/v466/n7308/full/nature09260.html.
- ^ A. Hernando, D. Villuendas, C. Vesperinas, M. Abad, A. Plastino (2009). "Unravelling the size distribution of social groups with information theory on complex networks". arXiv:0905.3704 [physics.soc-ph]., submitted to European Physics Journal B
- ^ André A. Moreira, Demétrius R. Paula, Raimundo N. Costa Filho, José S. Andrade, Jr. (2006). "Competitive cluster growth in complex networks". arXiv:cond-mat/0603272 [cond-mat.dis-nn].
- Albert R., Barabási A.-L. (2002). "Statistical mechanics of complex networks". Rev. Mod. Phys. 74: 47–97. Bibcode 2002RvMP...74...47A. doi:10.1103/RevModPhys.74.47. http://www.nd.edu/~networks/Publication%20Categories/publications.htm#anchor-allpub0001.
- Amaral, LAN, Scala, A., Barthelemy, M., Stanley, HE. (2000). "Classes of behavior of small-world networks". Proc. Natl. Acad. Sci. U.S.A. 97 (21): 11149–52. arXiv:cond-mat/0001458. doi:10.1073/pnas.200327197. PMC 17168. PMID 11005838. http://www.pubmedcentral.nih.gov/articlerender.fcgi?tool=pmcentrez&artid=17168.
- Barabási, Albert-László (2004). Linked: How Everything is Connected to Everything Else. ISBN 0-452-28439-2.
- Barabási, Albert-László; Bonabeau, Eric (May 2003). "Scale-Free Networks" (PDF). Scientific American 288 (5): 60–9. doi:10.1038/scientificamerican0503-60. http://www.nd.edu/~networks/Publication%20Categories/01%20Review%20Articles/ScaleFree_Scientific%20Ameri%20288,%2060-69%20(2003).pdf.
- Dan Braha, Yaneer Bar-Yam (2004). "Topology of Large-Scale Engineering Problem-Solving Networks" (PDF). Phys. Rev. E 69: 016113. doi:10.1103/PhysRevE.69.016113. http://necsi.edu/affiliates/braha/Topology--of--Large--Scale--Design--PRE69.pdf.
- Caldarelli G. "Scale-Free Networks" Oxford University Press, Oxford (2007).
- Caldarelli G., Capocci A., De Los Rios P., Muñoz M.A. (2002). "Scale-free networks from varying vertex intrinsic fitness". Physical Review Letters 89 (25): 258702. arXiv:cond-mat/0207366. Bibcode 2002PhRvL..89y8702C. doi:10.1103/PhysRevLett.89.258702. PMID 12484927.
- R. Cohen, K. Erez, D. ben-Avraham and S. Havlin (2000). "Resilience of the Internet to Random Breakdowns". Phys. Rev. Lett. 85: 4626–8. Bibcode 2000PhRvL..85.4626C. doi:10.1103/PhysRevLett.85.4626. http://link.aps.org/doi/10.1103/PhysRevLett.85.4626.
- R. Cohen, K. Erez, D. ben-Avraham and S. Havlin (2001). "Breakdown of the Internet under Intentional Attack". Phys. Rev. Lett. 86: 3682–5. Bibcode 2001PhRvL..86.3682C. doi:10.1103/PhysRevLett.86.3682. PMID 11328053. http://link.aps.org/doi/10.1103/PhysRevLett.86.3682.
- A.F. Rozenfeld, R. Cohen, D. ben-Avraham, S. Havlin (2002). "Scale-free networks on lattices". Phys. Rev. Lett. 89. http://havlin.biu.ac.il/Publications.php?keyword=Scale-free+networks+on+lattices&year=*&match=all.
- Dangalchev, Ch. (2004). "Generation models for scale-free networks". Physica A 338.
- Dorogovtsev, Mendes, J.F.F. , Samukhin, A.N. (2000). "Structure of Growing Networks: Exact Solution of the Barabási—Albert's Model". Phys. Rev. Lett. 85 (21): 4633. Bibcode 2000PhRvL..85.4633D. doi:10.1103/PhysRevLett.85.4633. PMID 11082614.
- Dorogovtsev, S.N., Mendes, J.F.F. (2003). Evolution of Networks: from biological networks to the Internet and WWW. Oxford University Press. ISBN 0-19-851590-1.
- Dorogovtsev, S.N., Goltsev A. V., Mendes, J.F.F. (2008). "Critical phenomena in complex networks". Rev. Mod. Phys. 80: 1275. Bibcode 2008RvMP...80.1275D. doi:10.1103/RevModPhys.80.1275.
- Dorogovtsev, S.N., Mendes, J.F.F. (2002). "Evolution of networks". Advances in Physics 51: 1079–1187. doi:10.1080/00018730110112519.
- Erdős, P.; Rényi, A. (1960) (PDF). On the Evolution of Random Graphs. 5. Publication of the Mathematical Institute of the Hungarian Academy of Science. pp. 17–61. http://www.math-inst.hu/~p_erdos/1960-10.pdf.
- Faloutsos, M., Faloutsos, P., Faloutsos, C. (1999). "On power-law relationships of the internet topology". Comp. Comm. Rev. 29: 251. doi:10.1145/316194.316229.
- Li, L., Alderson, D., Tanaka, R., Doyle, J.C., Willinger, W. (2005). "Towards a Theory of Scale-Free Graphs: Definition, Properties, and Implications (Extended Version)". arXiv:cond-mat/0501169 [cond-mat.dis-nn].
- Kumar, R., Raghavan, P., Rajagopalan, S., Sivakumar, D., Tomkins, A., Upfal, E. (2000). "Stochastic models for the web graph". Proceedings of the 41st Annual Symposium on Foundations of Computer Science (FOCS). Redondo Beach, CA: IEEE CS Press. pp. 57–65. http://www.cs.brown.edu/research/webagent/focs-2000.pdf.
- Manev R., Manev H. (2005). "The meaning of mammalian adult neurogenesis and the function of newly added neurons: the "small-world" network". Med. Hypotheses 64 (1): 114–7. doi:10.1016/j.mehy.2004.05.013. PMID 15533625. http://linkinghub.elsevier.com/retrieve/pii/S0306987704003524.
- Matlis, Jan (November 4, 2002). "Scale-Free Networks". http://www.computerworld.com/networkingtopics/networking/story/0,10801,75539,00.html.
- Newman, Mark E.J. (2003). "The structure and function of complex networks". arXiv:cond-mat/0303516 [cond-mat.stat-mech].
- Pastor-Satorras, R., Vespignani, A. (2004). Evolution and Structure of the Internet: A Statistical Physics Approach. Cambridge University Press. ISBN 0521826985.
- Pennock, D.M., Flake, G.W., Lawrence, S., Glover, E.J., Giles, C.L. (2002). "Winners don't take all: Characterizing the competition for links on the web". Proc. Natl. Acad. Sci. U.S.A. 99 (8): 5207–11. doi:10.1073/pnas.032085699. PMC 122747. PMID 16578867. http://www.modelingtheweb.com/.
- Robb, John. Scale-Free Networks and Terrorism, 2004.
- Keller, E.F. (2005). "Revisiting "scale-free" networks". BioEssays 27 (10): 1060–8. doi:10.1002/bies.20294. PMID 16163729. http://www3.interscience.wiley.com/cgi-bin/abstract/112092785/ABSTRACT.
- Onody, R.N., de Castro, P.A. (2004). "Complex Network Study of Brazilian Soccer Player". Phys. Rev. E 70: 037103. arXiv:cond-mat/0409609. doi:10.1103/PhysRevE.70.037103.
- Reuven Cohen, Shlomo Havlin (2003). "Scale-Free Networks are Ultrasmall". Phys. Rev. Lett. 90 (5): 058701. arXiv:cond-mat/0205476. Bibcode 2003PhRvL..90e8701C. doi:10.1103/PhysRevLett.90.058701. PMID 12633404. http://havlin.biu.ac.il/Publications.php?keyword=Scale-Free+Networks+are+Ultrasmall&year=*&match=all.
External links
- snGraph Optimal software to manage scale-free networks.
- The Erdős Webgraph Server describing the hyperlink structure of a weekly updated, constantly increasing portion of the WWW.